Coverage
This will cover the details and question that could be had around our coverage integration for the unit and E2E tests inside Yuba and github.
Questions
How does the coverage work?
We've got two places to get coverage when running the tests. From the test run them selfs and from the services the tests use. Both steps use the same tools Babel and istanbuljs/nyc.
For the test inside of jest
When getting the coverage from the test we use jest as the test framework it has config to instrumentation of our code using istanbuljs. It'll then save this and generate report outputs.
This is a simplified over view of what jest does to run test and how it instrumentation our code. There's a lot of steps around caching, vm setup and state that are skipped
sequenceDiagram
Jest->>Runtime: Create Runtime object
Runtime->>Jest: Ready need tests suit
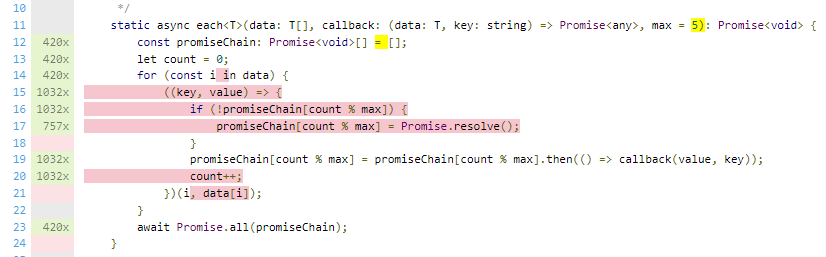
Jest->>Runtime: List of test file to process. Run them x at a time
loop Create x runner process
Runtime->>Runner: Process ready
Runtime->>Runner: Process this test file
Runner->>Transformer: Can you format this test file?
loop Every imported file found
Transformer->>TsJest: Here's a ts file give back js
TsJest->>Transformer: JS format back
Transformer->>Bable: Can you Instrumentation this js?
Bable->>Istanbuljs: Instrumentation these parts of js
Istanbuljs->>Bable: Done
Bable->>Transformer: Done
end
Transformer->>Runner: Done
Runner->>Runner: Create vm and push file data to setup test environment
Runner->>Runner: Run test suit
Runner->>Runtime: Test results and coverage
Runner->>Runner: Run clean up to be ready for next test or be killed because of resource limit
end
Runtime->>Jest: All tests done
Runtime->>Jest: Push results
Jest->>Jest: format coverage object using sourcemap to normalize "istanbul-lib-source-maps"<br/>Merge coverage object into global coverage object
Jest->>Jest: Pass test results to reports "testResultsProcessor" to display or write to disk
Jest->>Jest: Check if we've hit all the files we've been asked to coverage "collectCoverageFrom"
loop Found some files not used by the tests. For each file get coverage
Jest->>Runner: Process this none test file
Runner->>Transformer: Can you format this test file?
Transformer->>Runner: Done
Runner->>Jest: Here's the coverage result
Jest->>Jest: Format coverage object using sourcemap to normalize "istanbul-lib-source-maps"<br/>Merge coverage object into global coverage object
end
Jest->>Jest: Pass coverage result to reports "coverageReporters" to display or write to diskIn our case we set the reporters to ['json', 'lcov', 'clover']. The coverage directory is <rootDir>./coverage inside that dirrecotry you'll find a file called coverage-final.json with the coverage data from the code ran by the jest tests.
For the services
For the services we'll need to instrumentation our code when building and bundles of the service. We use a env value(export ENABLE_COVERAGE=true) to trigger this special output build. When we load the webpack config for the service we check the env value is present we add an extra loader.
The way webpack builds is a little like this
sequenceDiagram
Webpack->>Webpack: process config
Webpack->>Rules: Found file
opt Does the file name match a rules regex?
Rules->>MatchedRule: process file
MatchedRule->>LoaderA: File data
LoaderA->>Webpack: Found imported file that's need
LoaderA->>MatchedRule: Formatted file data
MatchedRule->>LoaderB: Formatted file data from preview loader
LoaderB->>MatchedRule: Formatted file data
endwith out webpack config the build would look like this
sequenceDiagram
Webpack->>Webpack: process config
Webpack->>FileProcessList: add ./src/app.ts to list
loop Found file .ts file
alt If external file
FileProcessList->>FileProcessList: Put a require to the file inside the bundle
else If internal file
FileProcessList->>Rule: Found file .ts file match to rule
Rule->>Transform: process file
activate Transform
Transform->>Fork: Add file to be processed by plugins in fork
Transform->>TsLoader: Here the file data to be formate
TsLoader->>Transform: Done without checking type<br/>return formatted file and sourcemap
TsLoader->>FileProcessList: Found a imported file add to list of files to process
Transform->>babelLoader: Formatted data and sourcemap from "ts-loader"
babelLoader->>Istanbuljs: Pass parts of code to Istanbuljs to be Instrumentation using "babel-plugin-istanbul"
Istanbuljs->>babelLoader: Done
babelLoader->>Transform: Done
Transform->>FileProcessList: Done with file
deactivate Transform
end
end
Note over Fork,TypeCheckFork: This happens at the same time as the Transform on a separate process
Fork->>TypeCheckFork: Run type check on each file added
TypeCheckFork->>Webpack: Push errors to fail process if exists
Fork->>LinterCheckFork: Run linter check on each file added
LinterCheckFork->>Webpack: Push errors to fail process if exists
Webpack->>optimization: minimize(and some other steps) all processed data that's going to be put in the bundle
optimization->>Webpack: Done
Webpack->>Webpack: Join all data and write to disk inside bundle.js<br/>Take sourcemap and write to disk inside bundle.js.mapA output instrumented file will look something like this (some comments to explain stuff)
"use strict";
/* istanbul ignore next */
function cov_2bl45rn0sq() { // This returns the state object that will change as code is run
var path = "yuba-monorepo/packages/service/ashitaka/src/app.ts"; // file location
var hash = "6d54c0ef00a82c3ba468cdd326e7c6543c0698bb"; // file hash
var global = new Function("return this")();
var gcv = "__coverage__"; // This is the name of the global object we store in
var coverageData = {
path: "yuba-monorepo/packages/service/ashitaka/src/app.ts",
statementMap: { // list of statements and where they are in the original code
"0": {
start: {line: 2, column: 0},
end: {line: 2, column: 62}
}
},
fnMap: { // function location
"0": {
name: "(anonymous_0)",
decl: {
start: {line: 7, column: 1},
end: {line: 7, column: 2}
},
loc: {
start: {line: 7, column: 13},
end: {line: 13, column: 1}
},
line: 7
}
},
branchMap: { // branching location to trace if we've gone down each option
"0": {
loc: {
start: {line: 6, column: 17},
end: {line: 6, column: 45}
},
type: "binary-expr",
locations: [{
start: {line: 6, column: 17},
end: {line: 6, column: 37}
}, {
start: {line: 6, column: 41},
end: {line: 6, column: 45}
}],
line: 6
}
},
s: {"0": 0, "1": 0, "2": 0, "3": 0, "4": 0, "5": 0, "6": 0}, // These are the stats the count up each time we run that part of the code
f: {"0": 0},
b: {"0": [0, 0]},
inputSourceMap: { // sourcemap used and original source code. We use this to normalize the traced location above
version: 3,
file: "yuba-monorepo/packages/service/ashitaka/src/app.ts",
sourceRoot: "",
sources: ["yuba-monorepo/packages/service/ashitaka/src/app.ts"],
names: [],
mappings: ";;AACA,8BAA4B;AAC5B,0DAAoD;AACpD,uDAAkD;AAGlD,MAAM,QAAQ,GAAG,OAAO,CAAC,GAAG,CAAC,QAAQ,IAAI,IAAI,CAAC;AAE9C,CAAC,KAAK,IAAmB,EAAE;IACvB,MAAM,IAAI,qBAAS,EAAE;SAChB,aAAa,CAAC,sBAAS,CAAC;SACxB,UAAU,EAAE;SACZ,QAAQ,CAAC,QAAQ,CAAC;SAClB,KAAK,EAAkB,CAAC;AACjC,CAAC,CAAC,EAAE,CAAC",
sourcesContent: ["\nimport '@product-live/boot';\nimport {AppModule} from './modules/main/app.module';\nimport {Bootstrap} from '@product-live/yuba-core';\nimport {AshitakaConfig} from './AshitakaConfig';\n\nconst APP_PORT = process.env.APP_PORT || 3000;\n\n(async (): Promise<void> => {\n await new Bootstrap()\n .withAppModule(AppModule)\n .withRabbit()\n .withPort(APP_PORT)\n .start<AshitakaConfig>();\n})();\n"]
},
_coverageSchema: "1a1c01bbd47fc00a2c39e90264f33305004495a9",
hash: "6d54c0ef00a82c3ba468cdd326e7c6543c0698bb"
};
var coverage = global[gcv] || (global[gcv] = {});
if (!coverage[path] || coverage[path].hash !== hash) {
coverage[path] = coverageData;
}
var actualCoverage = coverage[path];
{
// @ts-ignore
cov_2bl45rn0sq = function () {
return actualCoverage;
};
}
return actualCoverage;
}
cov_2bl45rn0sq(); // Each file as a seperate magic function name
cov_2bl45rn0sq().s[0]++;
Object.defineProperty(exports, "__esModule", ({
value: true
}));
/* istanbul ignore next */
cov_2bl45rn0sq().s[1]++;
__webpack_require__(2); // This is what a import looks like in webpack
const app_module_1 =
/* istanbul ignore next */
(cov_2bl45rn0sq().s[2]++, __webpack_require__(7));
const yuba_core_1 =
/* istanbul ignore next */
(cov_2bl45rn0sq().s[3]++, __webpack_require__(391));
const APP_PORT =
/* istanbul ignore next */
(cov_2bl45rn0sq().s[4]++,
/* istanbul ignore next */
(cov_2bl45rn0sq().b[0][0]++, process.env.APP_PORT) ||
/* istanbul ignore next */
(cov_2bl45rn0sq().b[0][1]++, 3000));
/* istanbul ignore next */
cov_2bl45rn0sq().s[5]++;
(async () => {
/* istanbul ignore next */
cov_2bl45rn0sq().f[0]++;
cov_2bl45rn0sq().s[6]++;
await new yuba_core_1.Bootstrap().withAppModule(app_module_1.AppModule).withRabbit().withPort(APP_PORT).start();
})();As you can see there's a lot of istanbul ignore next this is to help skip tracking on stuff not in the original source code.
When we run this service we now have access to a global object global.__coverage__ that tracks whats been run. We simply serve this data from endpoint to be used at any point.
@Get()
async getCoverage(): Promise<any> {
const coverageMap = libCoverage.createCoverageMap(global.__coverage__);
return new SkipFormatFiler(coverageMap.toJSON());
}Processing the coverage reports
After the tests are done this will leave us with coverage data in a few location after they've done running.
- Inside each test folder example:
['./package/test/e2e/', './lib/util/', ...]when run outside of the CICD or inside./package/coveragewhen run on the CICD - On all the running services from the endpoint
http://service/coverage
The few steps we need to take are finding each coverage-final.json file and transform them using their source map then we merge them into our global coverage object in memory. We then request each service and if they respond with an object we transform it using the source map found in the object(look at the transfromed file for an example of this). We then merge that transformed response data from the api into our global coverage object. When done we generate a html report file to disk and write the raw global coverage object to coverage-final.json.
All these steps are done with a little cli tool inside of ./package/cli/index.js. Example in the CI we pass the option "--coverage" to our sanity step to tell it to process coverage at the end of the tests.
npm run sanity -- --ready --cwd /app/packages/test/e2e --ci --coverage /app/packages/ --exec "npm run test:batch_0"There's other ways of running the coverage step
# This will merge mutliple coverage files to an output. Usefull when debuging the merge process
node cli coveragereport --input "cov1.json;cov2.json;cov3.json" --output merge-coverage.json
# This will try and find all source of coverage merge then into one and output a report
node cli coverage
node cli coverage --noreport # skip generating a html report file
node cli coverage --force # to skip the env value check
node cli coverage --coverage "./lib" # This will change the cwdHow to debug coverage problems
SWC coverage collect error
If your running the tests and have the coverage enabld. It may pass but you coverage generation at the end may throw an error. This is a problem with swc you can fix it by changing the version or updating it's config inside of ./package/jest.config.js there's a transform block config documentation.
ERROR: unknown field `strict`, expected `resolveFully` at line 1 column 466
STACK: Error: unknown field `strict`, expected `resolveFully` at line 1 column 466
Failed to collect coverage from /app/packages/service/ged/src/domain/converter/schedule.converter.tsSWC circular reference error
You may run your tests and get an error like this. This is most likely because of a circular reference in the code.
ReferenceError: Cannot access 'CommentThreadEntity' before initialization
3 | import {CommentThreadType, EntityTypes} from '@product-live/yuba-domain';
4 | import {DbObject} from '@product-live/yuba-nest-scaffold';
> 5 | import {CommentThreadReply} from '@product-live/yuba-domain';
| ^
6 | import {ItemSuggestionEntity} from '../matrix/entity/suggestion/ItemSuggestion.entity';
7 | import {CommentThreadAccountAssigneeEntity} from './comment-thread-account-assignee.entity';
8 |
at Object.get [as CommentThreadEntity] (../../lib/db-entities/src/comments/comment-thread.entity.ts:5:9)
at Object.<anonymous> (../../lib/db-entities/src/comments/comment-thread-account-assignee.entity.ts:28:24)
at CompileFunctionRuntime._execModule (../../node_modules/@side/jest-runtime/src/index.js:101:24)
at Object.<anonymous> (../../lib/db-entities/src/comments/comment-thread.entity.ts:10:45)
at CompileFunctionRuntime._execModule (../../node_modules/@side/jest-runtime/src/index.js:101:24)They're not all super clear. But in this example we can see comment-thread.entity and comment-thread-account-assignee.entity
In comment-thread-account-assignee.entity we see
@ManyToOne(() => CommentThreadEntity)
commentThread: CommentThreadEntity;In comment-thread.entity we see
@OneToMany(() => CommentThreadAccountAssigneeEntity)
accountAssignees: CommentThreadAccountAssigneeEntity[];The fix for this is to use Relation from TypeORM on the types that reference to each other. We should do this on TypeORM entities like so:
import {Relation} from 'typeorm';
....
@ManyToOne(() => CommentThreadEntity)
commentThread: Relation<CommentThreadEntity>;If it's not on a TypeORM entity. Maybe it's two services or more that are creating a circular reference and you don't want to refactor. Stupid example:
// file 1;
class WheelService {
consturctor(
@Inject(CarService) carService: CarService
) {}
canMove(): boolean {
return (this.carService.gas < 0);
}
}
// file 2;
class CarService {
occupent: string[] = [];
gas: number = 0;
consturctor(
@Inject(WheelService) wheelService: WheelService
) {}
canDrive(): boolean {
return (
this.wheelService.canMove() &&
this.occupent.length > 0
);
}
}You can change the @Inject type to use Type from import {Type} from '@product-live/yuba-domain' to this
@Inject(CarService) carService: Type<CarService>The magic we use is probably the same as Relation. The magic solution is a little anticlimactic.
export type Type<T> = T;SWC circular reference under the hood
You may think the fuck is going on? why? TSC doesn't seem to have a problem. The answer is it's because of the ESM spec on imports.
When you put the keyword type before it helps SWC make a difference between a value that can be used and be emitted to metadata and something that's only used as a helpfull type.
example output for the file "file1" WheelService from swc
const service = require("./carService.ts");
const lib = require("./type.ts"); // this will generate an empty file with no exports. This will equal {}
// with swc
public carService: Type<CarService>; // input
__metadata("design:type", typeof lib.Type === "undefined" ? Object : lib.Type); // output will always be Object
// without
public carService: CarService; // input
__metadata("design:type", typeof service.CarService === "undefined" ? Object : service.CarService); // output can be CarServiceYou may think what does this look like from TSC
const service = require("./carService.ts");
// (_a = typeof CarService !== "undefined" && service.CarService) will be "class CarService {}"
// (typeof CarService) is "function"
.__metadata("design:type", typeof (_a = typeof service.CarService !== "undefined" && service.CarService) === "function" ? _a : Object)They're both very similar. You'll basically get the same result with both outputs at runtime. You'll lose the same amount of metadata at runtime from both compilers.
- No circular reference you'll get
{"CarService": CarService}onserviceand so type in the metadata will beCarService - circular reference you'll get
{}onserviceand so type in the metadata will beObject
SWC throws the error during the compiler not during run. This is a check SWC does that TSC doesn't do because it's trying to match the ESM spec more closely.
Coverage merge problem
You may notice a low coverage value and when you look at the html report you'll have both red highlight and run counts on the line of code. If it's the case then it's probably a bad merge and the lines of code between jest and the services are different.
The source of the problem is either:
- The transformer/loader are not the same on jest and webpack.
- The transformer target output or other config is different.
- The coverage object is not getting formatted with the sourcemap.
- The coverage object is missing the sourcemap so can't be formatted.
You can confirm the problem by looking at the raw coverage. Pick a file look at "statementMap" you should see it'll have entries that cover the same lines just slightly off. It should line height should reset to the start of the file mid way thought the statement array.
{
0: {
start: {line: 12, column: 46}, // so we start a line 12
end: {line: 12, column: 48}
},
1: {
start: {line: 13, column: 20},
end: {line: 13, column: 21}
},
2: {
start: {line: 14, column: 8},
end: {line: 22, column: null}
},
3: {
start: {line: 15, column: 12},
end: {line: 21, column: 27}
},
4: {
start: {line: 16, column: 16},
end: {line: 18, column: null}
},
... // stip data
16: {
start: {line: 43, column: 12},
end: {line: 43, column: 22}
},
17: {
start: {line: 45, column: 8}, // got to the end of the file
end: {line: 45, column: 58}
},
18: {
start: {line: 2, column: 0}, // now we're back to the start?
end: {line: 2, column: 13}
},
19: {
start: {line: 2, column: 0},
end: {line: 2, column: 62}
},
20: {
start: {line: 3, column: 0},
end: {line: 3, column: 29}
},
21: {
start: {line: 13, column: 29}, // There's no line 12
end: {line: 13, column: 31}
},
22: {
start: {line: 14, column: 20},
end: {line: 14, column: 21}
},
... // stip data
34: {
start: {line: 45, column: 8},
end: {line: 45, column: 53}
},
35: {
start: {line: 48, column: 0},
end: {line: 48, column: 34}
}
}
}The solution
- Make sure jest is using jest-ts instead of swc
- Compare the two coverage objects from jest and the api
- Does the coverage object from the api change when passed thought the sourcemap transform inside the cli?
- Does the coverage object from the api have a sourcemap inside it?
Flaky tests from parallel runners
With the changes to add coverage we remove "runInBand" to speed everything up. Other tests are running actions on the database and services at the same time you'll have to keep this in mind when writing tests.
Check these
- Auto increment ID can be influenced by others. don't rely on the order.
- Not finding mail? Could be being removed.
- Time based steps could fail because of increased delay. Try using a trigger state.
- A job run can be slowed down from job runs in other tests.
- Use a new account for each test suit.
- Are actions finished from previous tests in the suit?
- Counting at the start of the test to subtract the final total can make tests more independent and retry friendly
Some tests failing are going to be hard to reproduce and fix or we may not have the time to refactor. In jest there's an option to retry put it in the describe block
jest.retryTimes(3, {logErrorsBeforeRetry: true}); // TODO: flaky test suit to fixI've put 3 in the example but you can go a lot higher if needed.
We've currently have a global configured(see "setupFilesAfterEnv") to have 2 retries when run with more then 1 worker to reduce frustration. This is not the best solution but it's cheap and fast solution until we fix the unstable tests.
An other solution is to increase the batch count or decrease the runner count. This will slow down the test or make them more expensive. This can be done with these settings in the PR body like so :
/test_e2e_batch_size 8
/worker_count 5OR change the default values found in .github/workflows/ci.yaml
How does the coverage integration into github
Actions
The CI/test running are split into multiple actions:
buildThis action builds any of the yuba image(node, basebuild, base, cli, test)cancelsends a cancel for a given action runsecurityscan code and generate security reportstestrun test batchciContinuous integration that runs all our test.
Actions: "ci"
ci.yaml is our continuous integration action that run on each commit. It's responsibilities are to make sure the image build works, all tests pass and generate coverage reports when needed.
This is what a run would look like on github. The numbers in red are to help link together with the flow chart below. 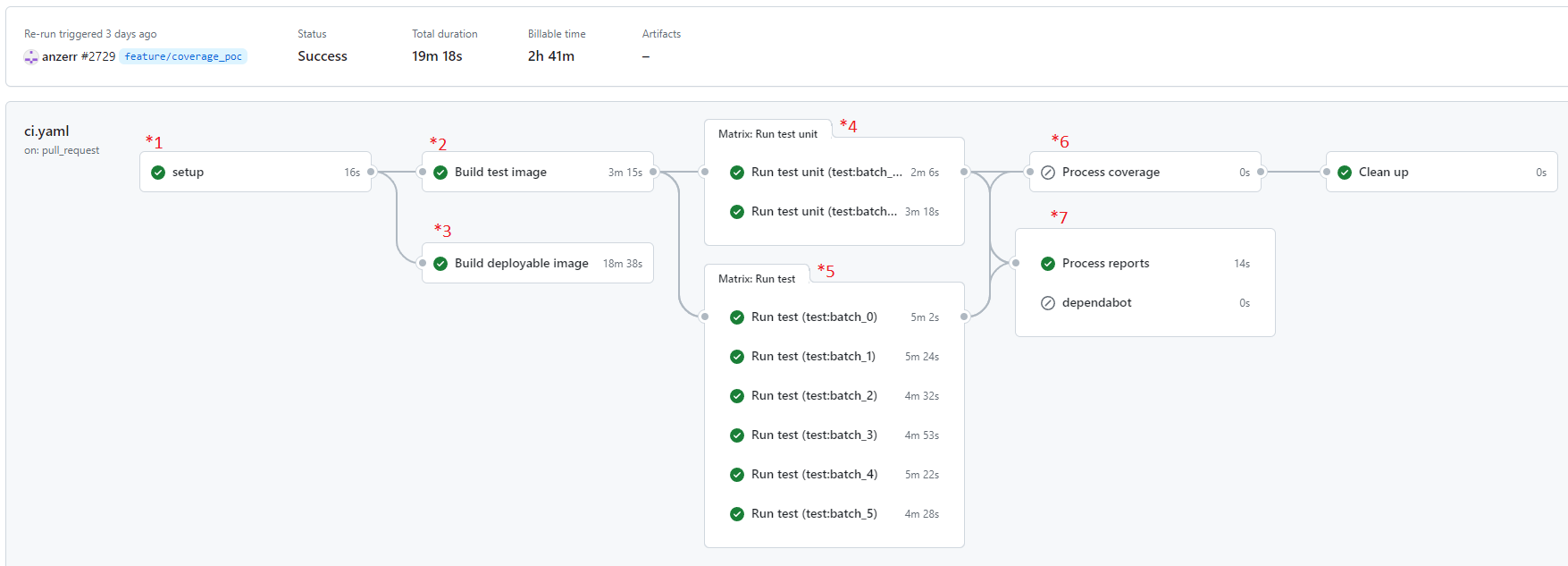
Here's what the flow of actions looks like for all the steps in ci.yaml and how/when the sub actions are used.
graph LR
classDef Box fill:white,stroke:#008bff
classDef Start stroke:green
classDef Done stroke:red
subgraph BuildAction["build/action.yaml"]
BuildAction_Checkout["Git check out"] -->
BuildAction_AzurePullLogin["Login into 'pull' azure docker registry"] -->
BuildAction_BuildImage["Build image set in 'input.service'"] --"skip"--> BuildAction_GenerateCompose
BuildAction_BuildImage --"If (input.push == 'true') then"-->
BuildAction_AzurePushLogin["Login into 'push' azure docker registry"] -->
BuildAction_PushImage["Push image to azure registry<br/>Image name will be `${input.image}:${input.tag}`"] -->
BuildAction_GenerateCompose["Generate docker compose file and extract result and package-lock file"] -->
BuildAction_UploadArtifact["Upload Files as artifact"] -->
BuildAction_Done["Done"]
end
class BuildAction Box
subgraph TestAction["test/action.yaml"]
TestAction_Checkout["Git check out"] -->
TestAction_AzurePushLogin["Login into 'push' azure docker registry"] -->
TestAction_Artifact["Download compose/lock artifact from github"] -->
TestAction_PullImage["Pull image set with 'inputs.image'"] -->
TestAction_AzurePullLogin["Login into 'pull' azure docker registry"] --"skip"--> TestAction_TestRun
TestAction_AzurePullLogin --"if (inputs.cache_key != '') then"-->
TestAction_RestoreCache["Restore cache from preview commit into './packages/cache'"] -->
TestAction_TestRun["Use compose and 'up' the needed services<br/>Wait for test container to exit"] --"use exit code to fail test"-->
TestAction_Collect["Collect result"]
TestAction_Collect --> TestAction_AResult["Test reports"] --"report_${env.TEST_NAME}"--> TestAction_UploadArtifact
TestAction_Collect --"if (inputs.coverage == 'true') then"--> TestAction_BResult["Coverage report"] --"coverage_${env.TEST_NAME}"--> TestAction_UploadArtifact
TestAction_Collect --"if (inputs.log == 'true') then"--> TestAction_CResult["Service logs"] --"logs_${env.TEST_NAME}"--> TestAction_UploadArtifact
TestAction_UploadArtifact["Upload collected files as artifact to github"] --"skip"--> TestAction_Done
TestAction_UploadArtifact --"if (inputs.cache_key != '') then"-->
TestAction_SaveCache["Save cache folder './packages/cache' and upload to github"] -->
TestAction_Done["done"]
end
class TestAction Box
subgraph Coverage["Coverage processing *6"]
Coverage_Checkout["Git check out"] -->
Coverage_AzurePushLogin["Login azure docker registry"] -->
Coverage_DownloadArtifact["Download all artifact uploaded in the action"] -->
Coverage_DockerPull["Pull test image from registry"] -->
Coverage_Merge["Run coverage cli to merge and generate html report using the test docker image"] -->
Coverage_UploadArtifact["Upload output report to github as artifact 'coverage_report'"]
end
class Coverage Box
subgraph Report["Test junit report processing *7"]
Report_Checkout["Git check out"] -->
Report_DownloadArtifact["Download all artifact uploaded in the action"] -->
Report_Process["Find all junit file '*.xml' and generate a report"]
end
class Report Box
subgraph Matrix["Matrix"]
Matrix_start["Start"]
Matrix_start <--> Matrix_action0["Action 1"] --> Matrix_done
Matrix_start <--> Matrix_action1["Action 2"] --> Matrix_done
Matrix_start <--> Matrix_action2["Action 3"] --> Matrix_done
Matrix_start <--> Matrix_actione["Action ..."] --> Matrix_done
end
class Matrix Box
Start["ci.yaml start"] --> Checkout["Git check out"] -->
Setup["Setup input values for the run *1"] --> tBuild["Build Test image *2"] -."Action Usage".-> BuildAction
Setup --> fBuild["Build full image *3"] -."Action Usage".-> BuildAction
tBuild --> MatrixInput["Run matrix of test action using input array"] -."Action used in matrix".-> TestAction
MatrixInput --> eMatrix["E2E test matrix *5"] -."Use".-> Matrix
MatrixInput --> uMatrix["Unit test matrix *4"] -."Use".-> Matrix
Matrix --"if (inputs.coverage == 'true') then"--> Coverage --> Cleanup
Matrix --> Report --> Cleanup
Cleanup["Clean up task"] --> Done["ci.yaml Finish"]
fBuild --> Cleanup
class Start Start
class Done DoneActions: "build"
The build action has all the logic needed to build all our different yuba images. It's used by the ci.yaml action to build the test image and full image we deploy. The ci.yaml action is a good action to understand the build actions usage.
The action inputs:
tag: what tag to put on the imageservice: What image to type to build (node, basebuild, base, cli, test)image: Image namecompose: Should generate compose file and with what argumentsartifact: The name of artifact we should upload lock and compose intopush: Should the built image be push to a registrybuild_base: Should the base "tool" layer be built or should remote version be usedcoverage: Should the services be built in coverage modetest_e2e_batch_size: How many e2e test batches to generate in the built imagetest_unit_batch_size: How many unit test batches to generate in the built imageparallel_build: How many webpack builds to be run at the same timeskip_lint: Should we skip running the linter in build
The different yuba image value that can be set service are:
node: Our"Tool"layer image used as base for all our other images.basebuild: This will build the full yuba image but stop at thebuildlayer and not clean upbase: This is the full yuba imagecli: The smallest/fastest image to build if you only need to use the yuba cli toolstest: The yuba test image. It skips clean up and it only builds the necessary service/worker used in the tests
Actions: "cancel"
Forces a cancel on a running action. We use this to help with error flow some steps are run if we have an error and some are run in all cases even a cancel. We use this to cancel the full build if the test image failed to build.
Actions: "security"
Currently not enabled. It contains the logic around scanning our code and generating security report.
Actions: "test"
This action is responsible for running a test batch. See the ci.yaml action for an example of it's usage.
The action inputs are:
image: The name of the image to be used in for the testsartifact: The name of the artifact used to load lock/compose fileslog: Should we collect the logs from the running services and upload as an artifactjest_bail_count: How many tests should fail before jest bailsjest_max_worker: How many workers/runners should jest recreate to run our suitstest: The name of the test batch we should runcache_key: The base cache keyskip_cache: Should we skip loading and updating cache filesnext_cache_tag: What cache key should we save intocurrent_cache_tag: What cache key should we load fromcoverage: Should we collect coverage and upload it as an artifact
The cache settings uses the github cache to save webpack and jest cache files to save some time when transpiling. We can't update/overwrite cache once it's created so we used the commit hashes to have unique cache entries. We load the cache from the previews commit hash and save into the current commit hash. Github cache have scope on the branch the action is running on.
Action: Configuration and coverage usage
Coverage can be generated from any PR or on for any branch when run by hand(workflow_dispatch). The easiest way is to add /coverage true to the body of your PR.
On the next test run you'll have a coverage file in the actions artifact. It's a zip with a html file you can inspect with chrome. You will also have the coverage for each test batch available but no report is generated.
If you need a report for these steps you can generate a html report using the cli in Yuba.
node cli coverage --directory ./coverage_test_batch_1 --force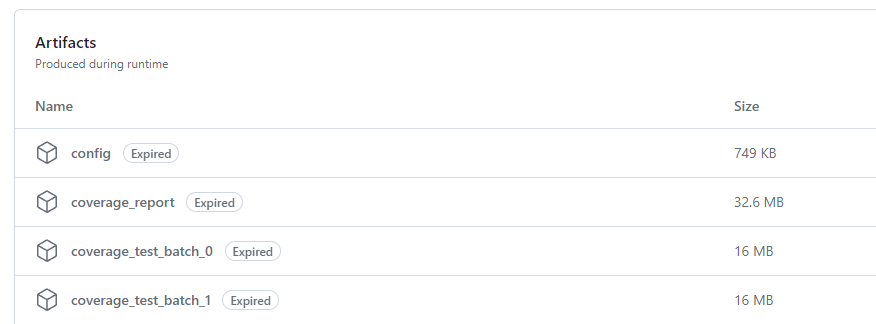
All action inputs can be set in the PR body using this format "/{config_name} value". Here's a list of all the inputs
debug: 'false', // collect and upload all the logs from the services for the test batch run
coverage: 'false', // should we collect coverage for the test run. This is slower
bail_count: '0', // How many tests should fail before we stop. 0 is disabled
worker_count: '10', // How many runner should jest create to run tests
build_base: 'true', // Should we rebuild the base image or use the remote image
test_e2e_batch_size: '6', // How many E2E batch to split the tests into
test_unit_batch_size: '1', // How many unit batch to split into
runner_large: 'ubuntu-latest-8-cores', // What runner to use for large task
runner_small: 'ubuntu-latest-8-cores', // what runner to use for mid task
runner_basic: 'ubuntu-latest' // what runner to use for small tasksThe value worker_count doesn't need to follow the machine core as most or our tests are fast/async. Because of the setup overhead for jest between runs we're saving most of our time allowing jest to setup in parallel. With one runner/worker we'll pass 60-99% of our time in jest and not running our tests.
Test batching and test naming standard
We currently batch our tests to have the ability to run them on separate actions/runners inside github. We added this layer of parallelization before allowing jest to run our tests in parallel with jest. It was an easier solution to have the tests run in separate enviroments.
The batching logic is simple.
- find all tests inside the project matching either
"*.test.ts"or"*.unit.ts"
- find all tests inside the project matching either
- split them into arrays of equal length.
This dumb solution gave us the better result that's why we dropped using test time in the batching. Tests combinations influence each others duration making it hard to create batch's using their duration.
We split our tests into two types
"*.test.ts"E2E tests should be named like this. They'll have access to all the services running in the compose stack."*.unit.ts"Unit tests should be named like this. They shouldn't need any outside resources to run. There's tests will be run without the compose stack running.
Coverage report
The generated html report is stand alone. The source map and source code is baked into it.
You got two view tree where you'll a directory structure. 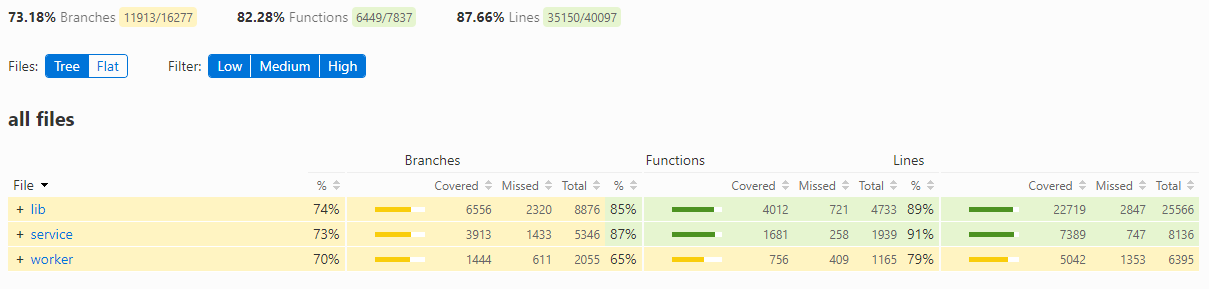
If you need a global view of the coverage flat is the best when using sort 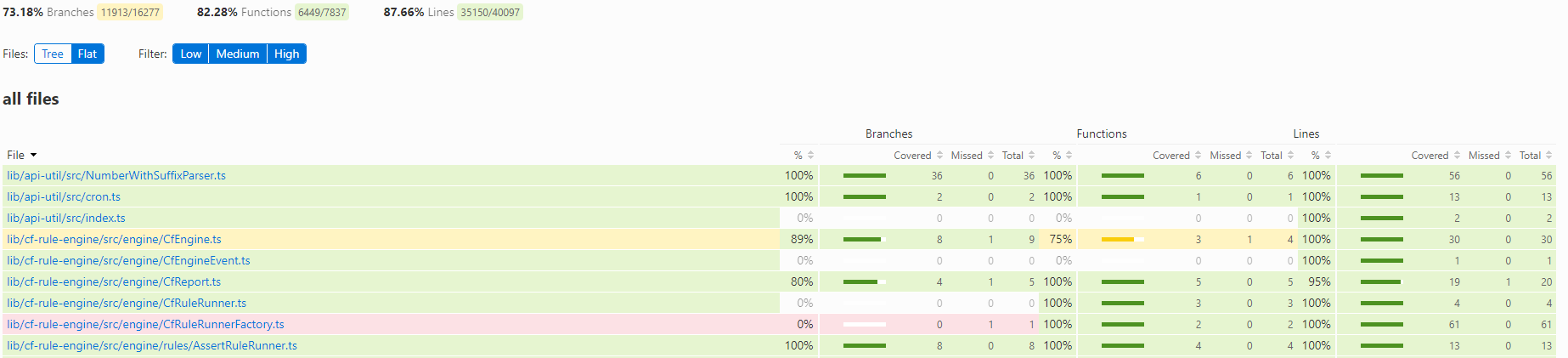
The columns Branch, Function and Lines each have the same data: how many instance or X, How many did we cover, how many did we miss with our tests.
BranchA branch and statement have overlap. A branch is a location that has a choose. Like an if, ternary, default value or switchFunctionFunctions will also encompasses the anonymous function. Sometimes the transpiler will transform things into anonymous functions. These functions are also coveredLinessimple the lines pass over
A file should look like this with the numbers of times a line has been visited 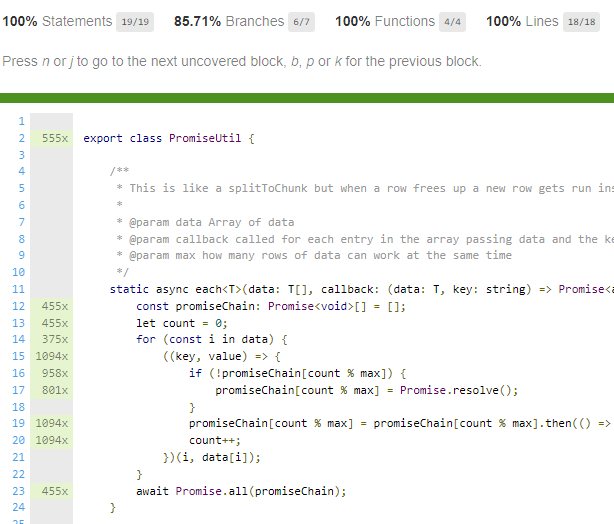
We the tests have not passed over a location it'll looks like this. There's hover elements to help tell you way's wrong 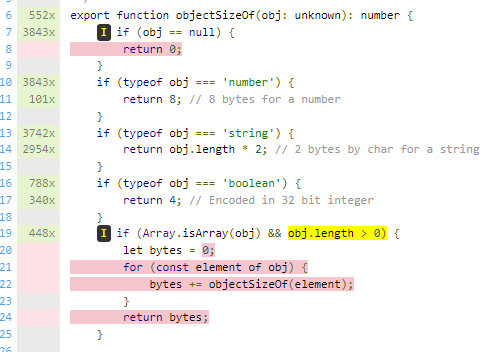
Iis an if branch not taken- red is code we've never run on hover it'll tell you
statement not covered - yellow is a branch not taken. This can happened on decorators and default values. It'll also sometimes show you it when it's something internal the TS to JS transpile.
The coverage should be taken with a grain of salt. It should be looked at as a way to find areas missing tests or find dead code to be removed. It's easy to build tests that'll increase the coverage but without increasing the confidence in your code base.
Tooling locations
When looking into this sometimes it helps to know where to start. Here's a list of code/config locations used for each step.
Action
All the code for the github actions can be found in
./.github/actionsthis will have all the reusable steps./.github/workflowsThis has the ci logic and put's all the actions to use./docker/imageThis had the dockerfile used to build the Yuba image used by the compose./docker/index.jsthis generates the compose file to run a test suit
Test Batching
All the code for batching tests can be found in
./packages/cli/util/tests.jsutil to find test files and batch them into groups./packages/cli/index.jsuses the util above to offer a cli./packages/test/e2e/package.jsonYou'll find all the scripts used to run the test. the cli also stores the batch commands in here.
Coverage helpers
All the code for coverage utils can be found in
./packages/cli/index.jscli code to use coverage util./packages/cli/util/coverageMerge.jsutil to merge coverage and generate and report./packages/cli/webpack.jsconfig to build a service with coverage enabled./docker/imagehas env value config used for coverage./packages/lib/nest-scaffold/src/nest/coverageModulesmall module to allow services to serve coverage data./packages/jest.config.jsconfig to generate coverage from test